











 William Charles
William Charles 0
0  2957
2957 405
405
Članak ažurirao Joel Lee dana 10.10.2017
Za mnoge Google je internet. To je polazna točka za pronalaženje novih stranica i, vjerojatno, najvažniji izum od samog interneta. Bez tražilica, novi web sadržaj bio bi nepristupačan masama.
Ali znate li kako funkcioniraju tražilice? Svaka tražilica ima tri glavne funkcije: indeksiranje (za otkrivanje sadržaja), indeksiranje (za praćenje i pohranjivanje sadržaja) i pretraživanje (za dohvaćanje relevantnog sadržaja kada korisnici traže tražilicu).
Puzeći
Pazenje je tamo gdje sve započinje: prikupljanje podataka o web mjestu.
To uključuje skeniranje web lokacija i prikupljanje detalja o svakoj stranici: naslovi, slike, ključne riječi, druge povezane stranice itd. Različiti alati za indeksiranje mogu također tražiti različite detalje, poput izgleda stranice, gdje se postavljaju reklame, jesu li veze ugurane itd..
Ali kako se pretražuje web stranica? Automatski bot (nazvan a “pauk”) posjetite stranicu za stranicom što je brže moguće pomoću linkova na stranicu da biste pronašli gdje dalje. Još u najranijim danima Googleovi pauci mogli su čitati nekoliko stotina stranica u sekundi. Danas ih je u tisućama.
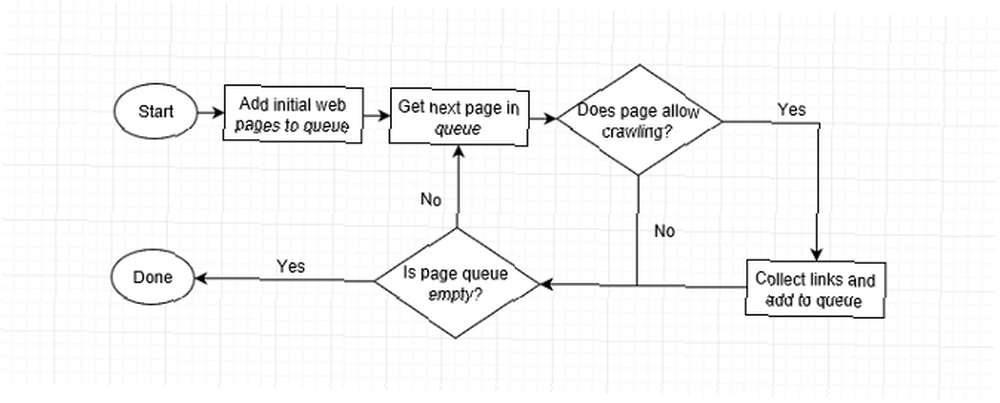
Kada web pretraživač posjećuje stranicu, prikuplja svaku vezu na stranici i dodaje ih na svoj popis sljedećih stranica koje će posjetiti. Prelazi na sljedeću stranicu na svom popisu, prikuplja veze na da stranicu i ponavlja. Web pretraživači također povremeno pregledavaju prošle stranice kako bi provjerili jesu li se dogodile neke promjene.
To znači da će svaka stranica koja je povezana sa indeksirane web lokacije na kraju biti indeksirana. Neke se web stranice češće pretražuju, a neke se izvode na veće dubine, ali ponekad se indeks može odustati ako je hijerarhija stranica web mjesta previše složena.
Jedan od načina da shvatite kako web alat za indeksiranje funkcionira jest da ga sami napravite. Napisali smo vodič o stvaranju osnovnog web alata za indeksiranje na PHP-u, pa provjerite imate li iskustva u programiranju.

Napominjemo da se stranice mogu označiti kao “noindex,” što je poput traženja pretraživača da preskoče njegovo indeksiranje. Neindeksirani dijelovi interneta poznati su i kao “duboka mreža” Što je Deep Web? Važnije je nego što mislite Što je Deep Web? Važnije je nego što mislite. Duboki i mračni web zvuče zastrašujuće i štetno, ali opasnosti su previdjene. Evo što oni zapravo čine i kako im možete sami pristupiti! , a neke web lokacije, poput onih koje se nalaze na TOR mreži, tražilice ne mogu indeksirati. (Što je TOR i luk usmjeravanje? Što je usmjeravanje luka, tačno? [MakeUseOf objašnjava] Što je luk usmjeravanje, tačno? [MakeUseOf objašnjava] Internet privatnost. Anonimnost je bila jedna od najvećih značajki Interneta u mladosti (ili jedna od njegove najgore karakteristike, ovisno o tome koga pitate). Ostavljajući po strani razne probleme koji izviru…)
indeksiranje
Indeksiranje je kada se podaci iz indeksiranja obrađuju i smještaju u bazu podataka.
Zamislite da napravite popis svih knjiga koje posjedujete, njihovih izdavača, njihovih autora, žanrova, broja stranica itd. Aziranje je kada češljate svaku knjigu, a indeksiranje je kad ih prijavite na svoj popis.
Sada zamislite da to nije samo soba puna knjiga, već svaka knjižnica na svijetu. To je mala inačica onoga što radi Google koji pohranjuje sve te podatke u ogromnim podatkovnim centrima s tisućama petabajtova pogonskih veličina Objašnjene memorije: Gigabajti, terabaji i petabajti u objašnjenim veličinama konteksta: Gigabajti, terabajti i petabaji u kontekstu Lako je vidjeti da je 500GB više od 100GB. Ali kako se uspoređuju različite veličine? Što je gigabajt na terabajtu? Gdje se uklapa petabajt? Razjasnimo! .
Evo zaviriti u jedan od Googleovih podatkovnih centara za pretraživanje:
 Kreditna slika: Google
Kreditna slika: Google
Dohvaćanje i rangiranje
Dohvaćanje je kad tražilica obrađuje vaš upit za pretraživanje i vraća najrelevantnije stranice koje odgovaraju vašem upitu.
Većina tražilica razlikuje se putem svojih metoda pretraživanja: koriste različite kriterije za odabir i odabir stranica koje najbolje odgovaraju onome što želite pronaći. Zato se rezultati pretraživanja razlikuju između Googlea i Binga i zašto je Wolfram Alpha tako jedinstveno koristan 10 cool upotrebe Wolfram Alpha ako čitate i pišete na engleskom jeziku 10 cool upotrebe Wolfram Alpha ako čitate i pišete na engleskom jeziku da mi se malo vremena omota oko glave Wolfram Alpha i upite koje on koristi da bi izbio te rezultate. Morate zaroniti duboko u Wolfram Alpha kako biste ga stvarno iskoristili za… .
Algoritmi za rangiranje provjeravaju vaš upit za pretraživanje milijarde stranica da odredite njihovu relevantnost. Tvrtke čuvaju svoje algoritme za rangiranje kao patentirane tajne industrije zbog svoje složenosti. Bolji algoritam znači bolje iskustvo pretraživanja.
Također ne žele da web tvorci igraju sustav i nepravedno se penju na vrhove rezultata pretraživanja. Ako se interna metodologija tražilice ikad izbaci, sve bi vrste sigurno to znanje iskoristile na štetu pretraživača poput vas i mene.
 Kreditna slika: fotovibe putem Shutterstocka
Kreditna slika: fotovibe putem Shutterstocka
Eksploatacija tražilice je moguće, naravno, ali to više nije lako.
Izvorno su tražilice rangirale web lokacije prema učestalosti pojavljivanja ključnih riječi na stranici “punjenje ključnih riječi” - punjenje stranica glupim ključnim riječima.
Zatim je došao koncept važnosti veza: pretraživači su cijenili web stranice s puno dolaznih veza jer su popularnost web mjesta protumačili kao relevantnu. Ali to je dovelo do spavanja neželjene pošte na cijelom webu. Danas vezne tražilice veze ovisno o “vlast” mjesta za povezivanje. Tražilice daju više vrijednosti na vezama vladine agencije nego vezama iz imenika veza.
Danas su algoritmi za rangiranje obavijeni više misterija nego ikad prije, i “optimizacija pretraživača” Demistificirajte SEO: 5 Vodiča za optimizaciju tražilice koji vam pomažu u početku Demistificirajte SEO: 5 Vodiči za optimizaciju tražilice koji vam pomažu u započinjanju svladavanja tražilice uzima znanje, iskustvo i puno pokušaja i pogrešaka. Možete početi učiti osnove i lako izbjegavati uobičajene pogreške u SEO uz pomoć mnogih SEO vodiča koji su dostupni na webu. nije toliko važno. Dobra ljestvica na tražilicama sada dolazi iz visokokvalitetnog sadržaja i sjajnog korisničkog iskustva.
Što slijedi za tražilice?
Ah, sada postoji zanimljivo pitanje. Odgovor je “semantika”: the značenje sadržaja stranice. Možete se pozabaviti našim pregledom semantičkog obilježavanja i njegovog budućeg utjecaja Što je semantička markacija i kako će se promijeniti Internet zauvijek [objašnjena tehnologija] Što je semantička markacija i kako će se promijeniti Internet zauvijek [objašnjena tehnologija] .
Ali ovdje je suština toga.
Sada možete tražiti “kolačići bez glutena” ali rezultati mogu vratiti recepte za kolačiće bez glutena. Umjesto toga, možete pronaći redovne recepte za kolačiće koji glase “Ovaj recept nije bez glutena.” Ima prave ključne riječi, ali pogrešno značenje.
Pomoću semantike možete pretraživati recepte za kolačiće i zatim ukloniti određene sastojke: brašno, orašaste plodove itd. Također možete suziti rezultate samo na recepte sa pripremnim vremenima manjim od 30 minuta i pregledati ocjene 4/5 ili više. Da bi bilo cool, zar ne? Kamo smo krenuli!
Još uvijek zbunjeni kako funkcioniraju tražilice? Pogledajte kako Google objašnjava postupak:
Ako vam se ovo učini zanimljivim, možda biste željeli saznati i kako slika tražilice rade.
Kreditna slika: prykhodov / Depositphotos