











 Mark Lucas
Mark Lucas 0
0  3365
3365 26
26
Cijelo vrijeme pričamo o tome da nas računala razumiju. Kažemo da je Google “znao” što smo tražili, ili onu Cortanu “dobio” što smo govorili, ali “razumijevanje” vrlo je težak koncept. Pogotovo kad je riječ o računalima.
Jedno polje računske lingvistike, zvano obrada prirodnog jezika (NLP), radi na ovom posebno teškom problemu. Trenutno je to fascinantno polje i kad jednom imate ideju o tome kako to funkcionira, počet ćete svugdje vidjeti njegove učinke.
Brza napomena: Ovaj članak sadrži nekoliko primjera računala kako reagira na govor, primjerice, kada Siri nešto zatražite. Transformacija zvučnog govora u računalno razumljiv format naziva se prepoznavanje govora. NLP se time ne bavi (barem u svojstvu o kojem ovdje raspravljamo). NLP dolazi u igru tek kada je tekst spreman. Oba su procesa potrebna za mnoge aplikacije, ali riječ je o dva vrlo različita problema.
Definiranje razumijevanja
Prije nego što se pozabavimo načinom na koji se računala bave prirodnim jezikom, moramo definirati nekoliko stvari.
Prije svega, trebamo definirati prirodni jezik. Ovo je jednostavan: svaki jezik koji ljudi redovno koriste spada u ovu kategoriju. To ne uključuje stvari poput konstruiranih jezika (Klingon, esperanto) ili računalnih programskih jezika. Kad razgovarate sa prijateljima, upotrebljavate prirodni jezik. Vjerojatno ga upotrebljavate i za razgovor sa svojim digitalnim osobnim pomoćnikom.
Pa što mislimo kad kažemo razumijevanje? Pa, to je složeno. Što znači razumjeti rečenicu? Možda biste rekli da to znači da sada imate željeni sadržaj poruke u svom mozgu. Razumijevanje koncepta može značiti da ga možete primijeniti na druge misli.
Definicije rječnika nejasne su. Nema intuitivnog odgovora. Filozofi se stoljećima svađaju oko ovakvih stvari.
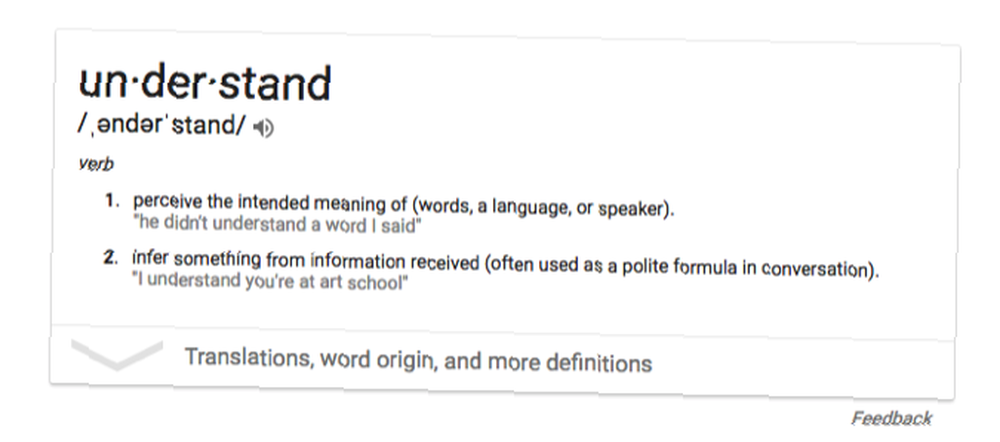
U naše ćemo svrhe reći da je razumijevanje sposobnost točnog izvlačenja značenja iz prirodnog jezika. Da bi računalo razumjelo, ono mora precizno obraditi dolazni tok govora, pretvoriti ga u jedinice značenja i biti u mogućnosti odgovoriti na ulaz s nečim što je korisno.
Očito je sve to vrlo nejasno. Ali najbolje je što možemo učiniti s ograničenim prostorom (i bez stupnja neurofilosofije). Ako računalo može ponuditi odgovor na struju prirodnog jezika nalik ljudskom ili barem korisno, možemo reći da razumije. Ovo je definicija koju ćemo upotrijebiti u naprijed.
Složen problem
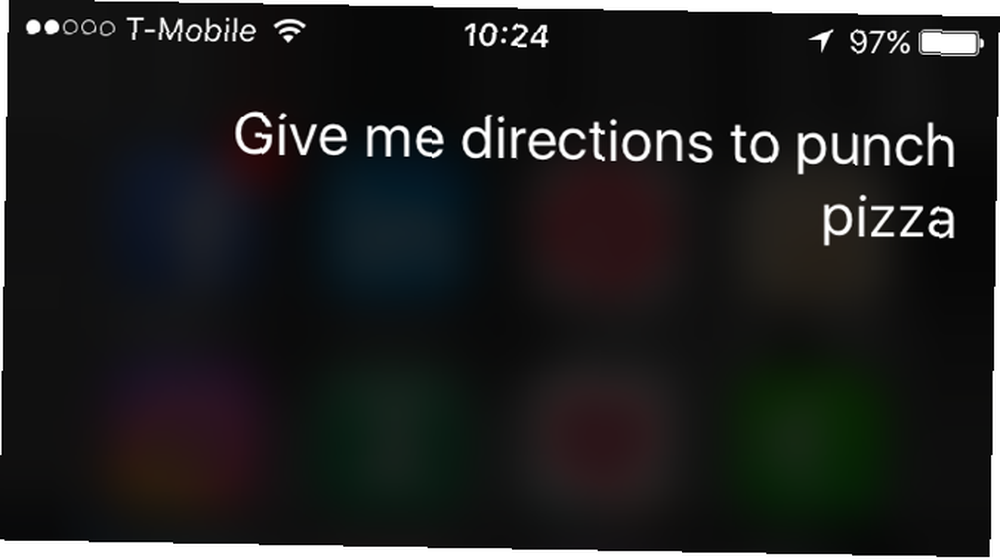
Prirodni je jezik vrlo težak za računalo. Možeš reći, “Siri, daj mi upute za Punch Pizza,” dok bih mogao reći, “Siri, Punch Pizza route, molim te.”
U vašoj izjavi Siri može odabrati ključnu frazu “dajte mi upute,” zatim pokrenite naredbu koja se odnosi na pojam za pretraživanje “Punch Pizza.” Međutim, u mom bi Siri morao izabrati “put” kao ključnu riječ i znajte to “Punch Pizza” je kamo želim ići, a ne “Molim.” I to je samo pojednostavljen primjer.
Razmislite o umjetnoj inteligenciji koja čita e-poštu i odlučuje mogu li biti prevare ili ne. Ili onaj koji nadzire postove na društvenim medijima kako bi utvrdio interes za određenu tvrtku. Jednom sam radio na projektu u kojem smo morali naučiti računalo čitati medicinske bilješke (koje sadrže sve vrste neobičnih konvencija) i prikupljati informacije od njih.
To znači da je sustav morao biti u mogućnosti nositi se sa skraćenicama, čudnom sintaksom, povremenim pravopisnim pogreškama i širokim nizom drugih razlika u bilješkama. To je vrlo složen zadatak koji može biti težak čak i iskusnim ljudima, a puno manje strojeva.
Postavljanje primjera
U ovom konkretnom projektu, bio sam dio tima koji je učio računalo da prepoznaje određene riječi i odnose između riječi. Prvi korak postupka bio je prikazivati računalu informacije koje sadrži svaka bilješka, pa smo ih napomenuli.
Bio je ogroman broj različitih kategorija entiteta i odnosa. Uzmi rečenicu “Glavobolja gospođice Green liječena je ibuprofenom,” na primjer. Gospođo Green označen je kao OSOBA, glavobolja označen je kao ZNAK ILI SIMPTOM, ibuprofen označen je kao MEDICACIJA. Tada je gospođu Green povezivala glavobolja s odnosom PREDSTAVNICI. Konačno, ibuprofen je bio povezan s glavoboljom sa TREATS odnosom.

Na ovaj smo način označili tisuće bilješki. Šifrirali smo dijagnoze, liječenja, simptome, temeljne uzroke, ko-morbiditet, doziranje i sve ostalo što biste se mogli sjetiti vezanih uz medicinu. Ostali timovi za napomene šifrirali su druge podatke, poput sintakse. Na kraju smo imali korpus pun medicinskih zabilješki koje je AI mogao “čitati.”
Čitanje je jednako teško odrediti koliko i razumijevanje. Računalo lako može vidjeti da ibuprofen liječi glavobolju, ali kad nauči te informacije, pretvara se u besmislene (nama) one i nule. Svakako može dati podatke koji se čine ljudskim i korisnim, ali je li to razumijevanje Što umjetna inteligencija nije, a što umjetna inteligencija nije, Jesu li inteligentni roboti roboti koji će preuzeti svijet? Ne danas - a možda i nikada. ? Opet, to je uglavnom filozofsko pitanje.
Pravo učenje
U tom je trenutku računalo prošlo kroz bilješke i primijenilo niz algoritama strojnog učenja 4 Algoritmi strojnog učenja koji oblikuju vaš život 4 Algoritmi strojnog učenja koji oblikuju vaš život Možda to ne shvaćate, ali strojno učenje je već oko vas, i može pokazati iznenađujuće stupanj utjecaja na vaš život. Ne vjerujete mi? Možda ćete se iznenaditi. , Programeri su razvili različite rutine za označavanje dijelova govora, analizu ovisnosti i biračke jedinice te označavanje semantičkih uloga. U biti, AI je učio “čitati” bilješke.
Istraživači bi ga mogli testirati tako da mu daju medicinsku bilješku i traže da označi svaki entitet i odnos. Kad je računalo točno reproduciralo ljudske napomene, mogli biste reći da je naučilo čitati navedene medicinske napomene.
Nakon toga bilo je samo prikupljanje ogromne količine statističkih podataka o onome što je pročitao: koji se lijekovi koriste za liječenje poremećaja, koji tretmani su najučinkovitiji, glavni uzroci specifičnih skupina simptoma i tako dalje. Na kraju postupka AI je mogao odgovoriti na medicinska pitanja na temelju dokaza iz stvarnih medicinskih zabilješki. To se ne mora osloniti na udžbenike, farmaceutske tvrtke ili intuiciju.
Duboko učenje
Pogledajmo još jedan primjer. Googleova neuronska mreža DeepMind uči čitati članke vijesti. Poput biomedicinskog AI gore, istraživači su željeli da izvadi relevantne i korisne informacije iz većih dijelova teksta.
Obuka AI o medicinskim podacima bila je dovoljno naporna, tako da možete zamisliti koliko će vam napomenutih podataka trebati da bi AI mogao čitati opće članke o vijestima. Zaposliti dovoljno annotatora i proći dovoljno informacija bilo bi neizmjerno skupo i dugotrajno.
Tako se tim DeepMind okrenuo drugom izvoru: vijestima s vijestima. Konkretno, CNN i Daily Mail.
Zašto ove stranice? Zato što daju sažetke svojih članaka koji su usmjereni na metke, a koji jednostavno ne povlače rečenice iz samog članka. To znači da AI ima od čega naučiti. Istraživači su u osnovi rekli AI, “Evo članka i ovdje su najvažnije informacije.” Tada su je tražili da istu vrstu informacija izvuče iz članka bez istaknutih istaknutih fotografija.
Ova razina složenosti može se nositi s dubokom neuronskom mrežom, koja je posebno komplicirana vrsta strojnog učenja. (Tim DeepMind čini nevjerojatne stvari na ovom projektu. Da biste saznali specifičnosti, pogledajte ovaj sjajni pregled iz MIT Technology Review.)
Što može učiniti AI čitanje?
Sada imamo općenito razumijevanje kako se računala uče čitati. Uzmete ogromnu količinu teksta, kažete računalu što je važno i primijenite neke algoritme strojnog učenja. Ali što možemo učiniti s AI koji povlači informacije iz teksta?
Već znamo da posebne medicinske informacije možete izvući iz medicinskih bilješki i sažeti opće novinske članke. Postoji program otvorenog koda koji se zove P.A.N. koja analizira poeziju izvlačeći teme i slike. Istraživači često koriste strojno učenje kako bi analizirali velika tijela podataka na društvenim mrežama, a kompanije ih koriste kako bi razumjeli osjećaje korisnika, vidjeli o čemu ljudi govore i pronašli korisne obrasce za marketing.
Istraživači su koristili strojno učenje kako bi stekli uvid u ponašanje e-pošte i učinke preopterećenja e-poštom. Davatelji usluga e-pošte mogu ga koristiti za filtriranje neželjene pošte iz pristigle pošte i klasificiranje nekih poruka kao prioritetnih. AI-ovi za čitanje su presudni za stvaranje učinkovitih chatova za korisničku službu 8 Botova koje biste trebali dodati svom Facebook Messenger App 8 Bots koje biste trebali dodati na vaš Facebook Messenger App Facebook Messenger otvorio se za chat botove, omogućujući tvrtkama da isporučuju korisničku uslugu, vijesti i još mnogo toga do vas putem aplikacije. Ovdje su neke od najboljih dostupnih. , Gdje god postoji tekst, postoji istraživač koji radi na obradi prirodnog jezika.
Kako se ova vrsta strojnog učenja poboljšava, mogućnosti se samo povećavaju. Računala su bolja od ljudi u šahu, Go-u i video igrama. Uskoro će im možda biti bolje u čitanju i učenju. Je li ovo prvi korak ka snažnom AI Evo zašto znanstvenici misle da biste se trebali brinuti zbog umjetne inteligencije Evo zašto znanstvenici misle da biste se trebali brinuti zbog umjetne inteligencije Mislite li da je umjetna inteligencija opasna? Da li AI može predstavljati ozbiljan rizik za ljudski rod. Ovo su neki od razloga zbog kojih biste mogli biti zabrinuti. ? Morat ćemo pričekati i vidjeti, ali može biti.
Koje se vrste koristi za AI za čitanje teksta i učenje? Koje ćete vrste strojnog učenja misliti u skoroj budućnosti? Podijelite svoje misli u komentarima u nastavku!
Slikovni krediti: Vasilyev Alexandr / Shutterstock